なんと!一度覚えたことをAIも忘れてしまう!?自動運転に向けての機械学習の取り組み

現代は人間の五感に代わるセンサーが発達し、自動運転・セキュリティシステムや産業オートメーション、ヘルスケアといった分野で多くのセンサーが使用されるようになってきました。特に最近では複数のセンサーから有意なデータを抽出し、それを融合するための深層学習によるセンサーフュージョン*¹が注目されています。京セラでは多くのセンサー部品を製造していますが、その使い方の研究も進めています。
*¹…センサーフュージョンとは、複数のセンサーからの情報を組み合わせて、周辺環境をより明確に把握できるようにする技術。自動車の自動運転ではカメラ・レーダ・ライダー (LiDAR)、ドローンではカメラ・地磁気センサー・ジャイロセンサーなどを組み合わせています。
目次
センサーフュージョンにおける効率的な学習方法とは?
京セラの先進技術研究所では、多くのセンサーを組み合わせて自動運転への応用を検討しています。車を運転するシチュエーションは、昼間や夜間、雨、雪など様々な状況が想定されます。このような状況下では、カメラのみ、LiDARのみのような単一のセンサーで対応することが困難です。例えば、カメラは夜間などの暗い環境下では解像力が高くても物体認識の性能が落ちてしまいます。対照的に、LiDARはカメラと比較すると解像力が低いですが、低照度であっても性能は劣化しません。そのため、複数のセンサーを組合せたセンサーフュージョンは、環境条件に対してロバスト性*²を向上するための解決策の一つです。
しかし、深層学習によるセンサーフュージョンでは、それぞれのセンサーに対して学習データと教師データが必要となるため、センサーの数が増えれば増える程、単一のセンサーよりもデータを収集するコストが高くなってしまうという問題があります。また、データ量の増大に伴い学習にかかる時間も増えてしまいます。
*²…ロバスト性とは、直訳すると強靭性・堅牢性のことを言うが、AIや機械学習の世界では特異なデータが出ても正確な予測が可能な性能のことを言う。
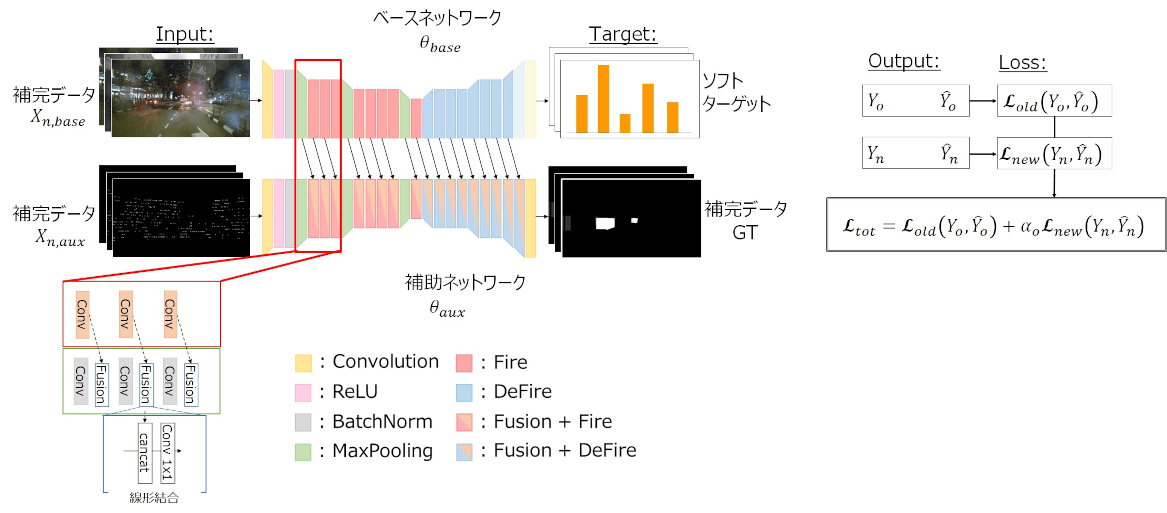
そこで、我々は少量データによるセンサーフュージョンの学習方法を開発しました。少量データで学習を行うために、ベースとなるセンサーで出来るだけ認識できるよう事前に深層学習のネットワークの学習を行い、ベースとなるセンサーでは認識が難しいシーンはセンサーを追加してネットワークの学習を行います。そのために、ベースとなるセンサーの苦手なデータのみを使います。開発手法のネットワークは、下図のようにベースネットワークと補助ネットワークから構成されます。
例えば、カメラをベースとなるセンサー、LiDARを追加するセンサーとして使用する場合を考えます。ベースとなるカメラの学習では、昼や夜、雨など使用が想定されるシーンを事前に学習しておきます。その後に、学習済みのカメラのネットワークにLiDARを追加します。LiDARの学習時にはカメラの苦手な夜や雨のシーンのみを学習します。この時、カメラの出力をLiDARを追加する前の出力にします。これにより事前に得た知識を失ってしまう破滅的忘却*³の発生を防ぎます。
*³…破滅的忘却とは、AIの典型的な欠点である「一度何かを学習したネットワークに新しいものを覚えさせようとすると、以前学習したものを忘れてしまう」こと
ニューラルネットワーク固有の欠点「破滅的忘却」に挑む!
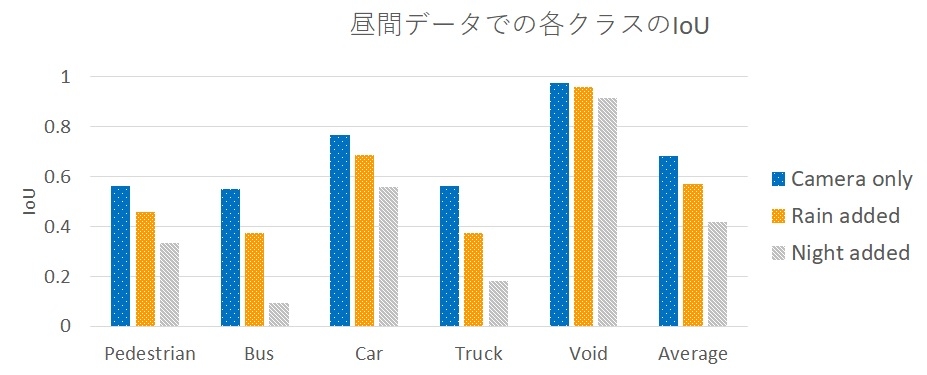
従来のセンサーフュージョンの学習方法では、昼、夜、雨のシーンを学習したカメラのネットワークに対して、夜もしくは雨を学習したLiDARのネットワークを追加します。画像中の物体が何かを分類するタスクで、グラフの横軸は対象物、縦軸はIoU*⁴を示しています。青の棒グラフは学習済みのカメラのネットワークを示し、オレンジは雨のシーン、グレーは夜のシーンで学習したLiDARのネットワークを追加した場合をそれぞれ示します。グラフから青よりも、オレンジとグレーの性能が落ちていることから忘却が発生していることが分かります。また、雨よりも夜の方が忘却の発生が大きいことが分かります。
*⁴…IoU(Intersection over Union)、画像の重なりの割合を表す指標で、IoUが大きいほど画像が重なっていることを意味する。具体的には、予測領域と正解領域が完全に重なる場合に最大値1、まったく重ならない場合に最小値0となる

上記画像の左上が入力画像です。この画像を元に道路上の人や車、その他の障害物をセグメンテーション(抽出)するタスクをAIに与えます。左下がGround Truth(GT:正解)、右上がファインチューニング、右下が提案手法です。ファインチューニングは忘却の影響のため画面中央で誤認識(FP:False Positive)、画面右端で未検知(FN:False Negative)となっています。一方、提案手法はGTに近いセグメンテーション結果が得られています。


なお、本技術は第27回 画像センシング技術研究会(SSII2021)にて優秀学術賞を受賞しました。画像センシング技術研究会は毎年6月頃に開催される画像認識分野の国内最大級の学会です。SSII2021はオンラインで開催され、2,000名以上の方が参加しました。優秀学術賞は、一般発表の中から学術的価値が高いものに与えられる賞です。
【表彰名称】第27回 画像センシングシンポジウム 優秀学術賞
【対象論文名】Multimodal Learning Without Forgetting
【受賞者(論文著者)】林 佑介(京セラ), 田口 賢佑(京セラ),森田 渉吾(京セラ), 金 在喆(京セラ), 藤吉 弘亘(中部大学)
さらに複雑化するセンサーフュージョンに向けて!
学習コストを低減しつつ、環境ロバスト性を向上する学習により、さらに多くのセンサーの情報を複合的に判断することが可能なセンサーフュージョン技術に取り組み、より安心・安全で扱いやすい自動運転システムに取り組んでいきたいと考えています。
将来的には、人間の五感である視覚、聴覚、嗅覚、味覚、触覚による外部からの様々な情報に基づいて考え、記憶し、判断できるセンサーフュージョン技術により、自動運転だけでなく人間の行動を予測するセキュリティシステム、生鮮食品の品質チェックを行う食品検査システム、オンライン会議参加者の共感・理解を認識するファシリテーション支援システムといった分野への応用を検討していきます。



